See the new FITLayout/2 at GitHub
The web page below refers to an outdated version of FITLayout. The new version includes a completely reworked Java API, a web GUI and much more. The complete documentation is available at GitHub.
FitLayout is an extensible web page segmentation and analysis framework written in Java. It defines a generic Java API for representing a rendered web page and its division to visual areas and it provides a base for implementing page segmentation algorithms with a common application interface. As a sample segmentation method, it implements a previously published segmentation algorithm based on recursive visual area merging and separator detection. The framework includes tools for post-processing the segmentation result by different text or visual classification methods. Finally, it also provides tools for controlling the segmentation process and examining the segmentation results through a graphical user interface. The segmentation result may be stored as RDF data for later analysis.
The FitLayout framework consists of the following modules (hosted on GitHub):
The API provides the common interface used for connection all the remaining modules. The framework allows to provide a custom implementation or extensions of any of the remaining modules. This allows replacing the default CSSBox rendering engine by another implementation and mainly, to implement and test custom page segmentation methods.
See also the FITLayout manual and the generated Javadoc documentation.
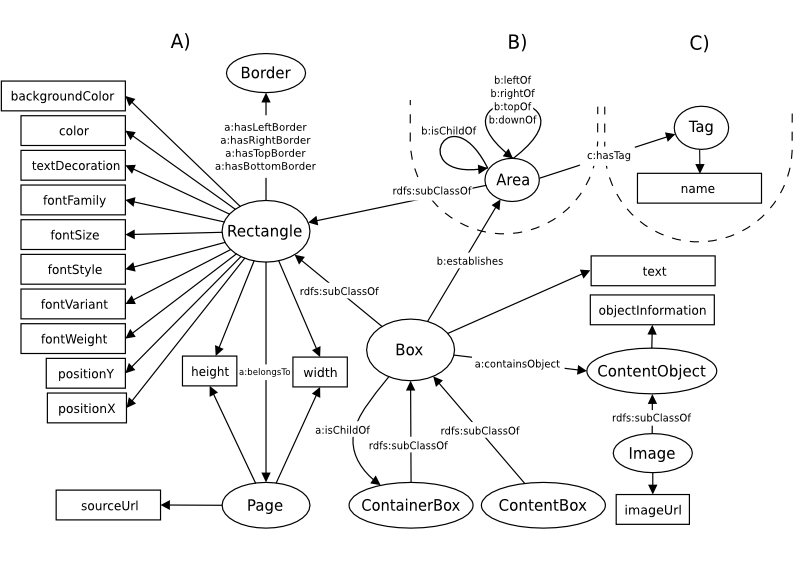
The API is based on an ontological description of the processed page as published in [1]. The related ontology is displated below. For each class from the ontology, the API defines a Java interface with the corresponding properties. These interfaces are avaliable in the org.fit.layout.model package.
Moreover, default implementations of the model interfaces are available in the org.fit.layout.impl package.
CSSBox is used as the default rendering engine. The CSSBox bindings provide an implementation of the box tree source. Based on a given URL, the rendering engine is used to create a set of boxes that correspond to the individual pieces of document content positioned in the page.
The segmentation module provides a generic framework for implementing web page segmentation algorithms. It represents the page as a tree of detected visual areas and defines an interface for implementing custom tree processing methods (operators) that implement the actual segmentation.
The default page segmentation algorithm is based on [2]. It uses a bottom-up approach that merges the individual boxes to larger visual areas. However, the FITLayout framework is open to adding other segmentation algorithms.
The result of the page segmentation is a tree of visual areas that are represented as the Area objects.
The individual visual areas detected during the page segmentation may be tagged with arbitrary tags. The classification package implements tagging the areas by classification of their visual properties as proposed in [3] or textual properties [4].
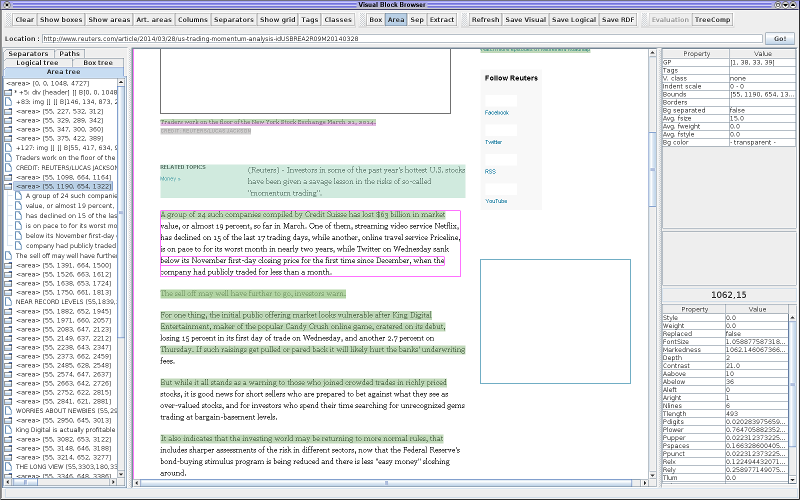
The tools allow to run the segmentaion on the given URL and examine the results by a GUI browser.
FITLayout is available under the terms of the GNU General Public License.
This work was supported by the BUT FIT grant FIT-S-14-2299 and the IT4Innovations Centre of Excellence CZ.1.05/1.1.00/02.0070.